Leaderboard


Popular Content
Showing content with the highest reputation on 11/19/2018 in Posts
-
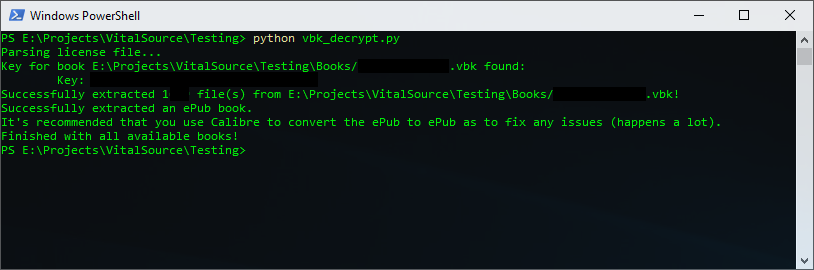
VBK Decrypt - A Python Script to Fully Remove VitalSource DRM The script is located here: [Hidden Content]= Please read the whole post before replying with issues. Screenshot of Successful Output So in the past few months, I've had my eye on a book that I could only find (in digital format, at least) on VitalSource. After doing some research on the DRM, I noticed that there's not any tools to strip the books of their DRM directly -- rather just images and such. After doing a bit of research on their DRM with some free books, I was able to figure out their DRM and crack it almost completely. The script I wrote will decrypt MOST VBK books, but it does not support the oldest algorithm "aes" (yet). Please note this only works on paid-for books! Prerequisites This script is made for Python 3 and is not yet backwards-compatible with Python 2, so please make sure you're using the right Python version before posting any issues. The libraries required are"PyCryptodome" and"img2pdf". They can be had by running"pip3 install pycryptodomex img2pdf" in an admin command prompt; please make sure you're using Python 3's pip. The files required for decryption can be found in:"%PUBLIC%\Documents\Shared Books\VitalSource Bookshelf" and/or"%USERPROFILE%\Documents\My Books\VitalSource Bookshelf" The files required for decryption are: Your "license.vbk" file (usually found in "%USERPROFILE%\Documents\My Books\VitalSource Bookshelf\User Data") The book(s) you want to decrypt & extract. This script was written by a Windows user with Windows in mind, but it should work for Mac OS/X (and others, if I have the private key for the license). Using the Script To use the script, I'd recommend you create its own folder and inside that folder, create a folder named Books for your actual VBK books. In the first folder you made, place the script and license.vbk file inside. To run the script, open command prompt and jump to the created directory or, while in the directory in your file explorer, simply hold shift, right-click, and click on "Open Powershell Here" or "Open Command Prompt Here". Enter "python vbk_decrypt.py" (or "py -3 vbk_decrypt.py", if Python 3 is not your default Python). After several seconds, it should be done extracting books to a folder called "Output"! The way I name the output files is by their decryption key, so please make sure to title your books yourselves. If your book is an ePub book, I recommend converting it to an ePub again using Calibre as to fix any mistakes that will likely occur. If your book is a PDF book, all of the work is done for you! If your book is picture book, all of the work is done for you except adding a table of contents to the PDF. If your book has an unknown format, the extracted files should be in the Output folder in its own folder -- let me know if you have an unknown format that you want supported by messaging me. Wanna Help Improve the Script? The code is pretty bad as I'm somewhat new to Python and it's a custom format -- if you feel there's something you want to add or improve, feel free to reply or message me. Change Log EDIT0: Fixed an issue with key parsing in some cases. EDIT1: Fixed an issue with copying extracted files from an unknown book format, added support for the "picturebook" format, and (attempted) to make paths compatible for most platforms. EDIT2: Added support for older Windows licenses; still looking into other platforms! EDIT3: Added support for Mac OS/X licenses. EDIT4: Came up with a less "hacky" method of parsing the filemap. Removed support for "picturebooks" as the library I used is incompatible with some Mac OS/X installs. I also now parse "bookInfo" in the footer's "metadata" element, so output files and folders are named after their book titles. EDIT5: Fixed an issue where the script would read the .DS_store file in the Books directory and assert an invalid header error. (Thanks, SPG!) EDIT6: Added support for Android licenses. EDIT7: Fixed an issue where "item" would show up as a result of decryption even if the key was invalid - allowing for an invalid key to be associated with a book. EDIT8: Fixed an issue with the "win2" private key not importing correctly (due to being encoded incorrectly). EDIT9: Now GDPR compliant!
 1 point
1 point -
A hard drive search engine this is a vital program for me for quick searching of all my hard drives. in less than a second, i can search for any author, book, title, etc. the second URL is a FAQ. i have used this for over 3 years and would be lost without it. [Hidden Content] [Hidden Content]faq/ Everything Search Engine Locate files and folders by name instantly. "Everything" is a filename search engine for Windows. How is Everything different from other search engines Small installation file. Clean and simple user interface. Quick file indexing. Quick searching. Quick startup. Minimal resource usage. Small database on disk. Real-time updating. mispelled Search in title.. i hate when i do that...
1 point
-
Another Source for Older Apps In addition to: oldversion.com and oldapps.com/index.php There is [Hidden Content]1 point
-
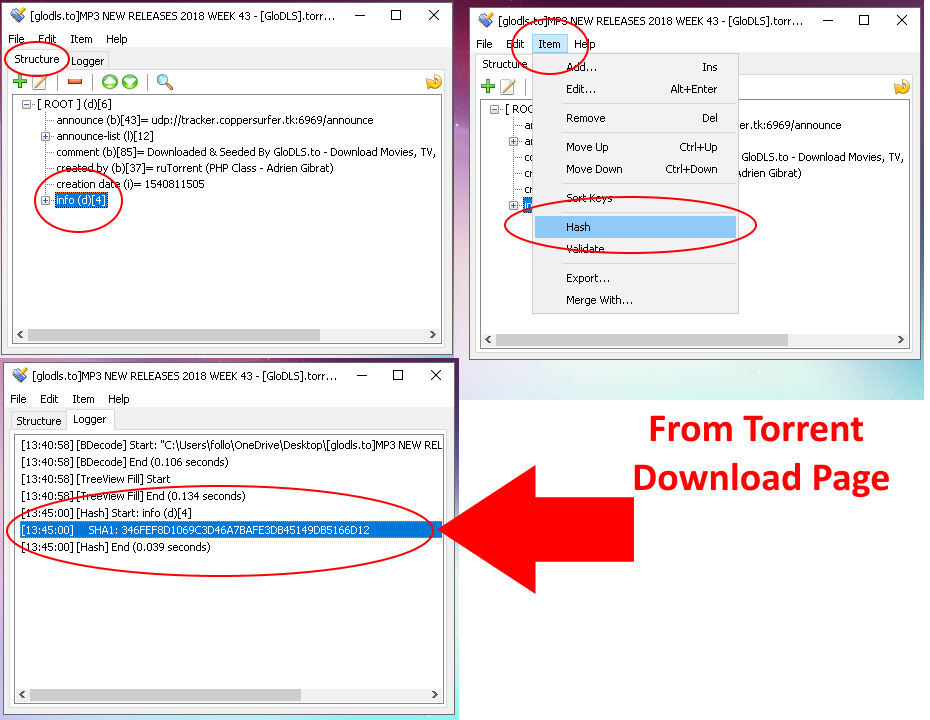
Checking Torrent Hash There are three main reasons to check the Torrent Info Hash: 1. You may have files that are already here that you wish to seed. Keep in mind that your unsatisfied count will be impacted, you will need to seed the torrent for the 72 hours minimum like any other torrent (book) downloaded. 2. You may have run into an error, sometimes due to the hash being changed on the data file (the book) and want to find out if this is the case and therefore if you need to re-download the book to get things squared away. 3. You may wish to fulfill a reseed request and are uncertain if the data file you have is the same exact one down to the info hash. You will need Ultima's BEncode Editor [Hidden Content] Then you proceed: Make note of the Info Hash as reported on the Torrent page Download the .torrent file from the site Create a new .torrent file from the data file (the book) you wish to check, but do not start it. Open both .torrent files with BEncode Editor and compare the info hash, If they match, you are good to go...
1 point